
프랙티스만이 살길. 프랙티스만이 살길.
1. Tensor 본문
PyTorch는 딥러닝을 위한 오픈 소스 라이브러리로, 텐서(Tensor)라는 다차원 배열을 다루는 데 사용됩니다. 텐서는 NumPy의 배열과 유사한 개념이지만, GPU를 활용한 병렬 계산과 자동 미분 등 딥러닝 연산에 최적화되어 있습니다.
torch.empty
주어진 크기(size)로 비어있는(empty) 텐서를 생성하는 함수입니다. 텐서의 요소는 초기화되지 않으며, 생성된 텐서의 값은 메모리 상태에 따라 랜덤한 값이 될 수 있습니다.

- size: 텐서의 크기를 나타내는 정수 또는 정수 튜플입니다. 예를 들어, torch.empty(2, 3)는 2행 3열 크기의 텐서를 생성합니다.
- out (선택적): 출력 텐서로 사용할 객체입니다. 이 매개변수를 지정하면 함수는 새로운 텐서를 생성하지 않고 주어진 객체를 반환합니다.
- dtype (선택적): 텐서의 데이터 타입을 지정합니다. 기본적으로는 torch.float32로 설정됩니다.
- layout (선택적): 텐서의 메모리 배치 방식을 지정합니다. 기본값은 torch.strided입니다.
- device (선택적): 텐서가 생성될 장치를 지정합니다. 기본적으로는 현재 기본 장치를 사용합니다.
- requires_grad (선택적): 텐서의 연산에 대한 그래디언트(gradient) 계산을 활성화할지 여부를 지정합니다. 기본값은 False입니다.
torch.rand
주어진 크기(size)로 랜덤한 값으로 초기화된 텐서를 생성하는 함수입니다. 텐서의 요소는 0과 1 사이의 균일 분포(uniform distribution)에서 랜덤하게 선택됩니다.
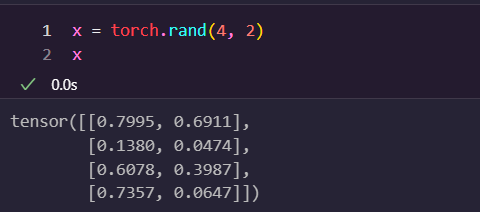
- size: 텐서의 크기를 나타내는 정수 또는 정수 튜플입니다. 예를 들어, torch.rand(2, 3)는 2행 3열 크기의 텐서를 생성합니다.
- out (선택적): 출력 텐서로 사용할 객체입니다. 이 매개변수를 지정하면 함수는 새로운 텐서를 생성하지 않고 주어진 객체를 반환합니다.
- dtype (선택적): 텐서의 데이터 타입을 지정합니다. 기본적으로는 torch.float32로 설정됩니다.
- layout (선택적): 텐서의 메모리 배치 방식을 지정합니다. 기본값은 torch.strided입니다.
- device (선택적): 텐서가 생성될 장치를 지정합니다. 기본적으로는 현재 기본 장치를 사용합니다.
- requires_grad (선택적): 텐서의 연산에 대한 그래디언트(gradient) 계산을 활성화할지 여부를 지정합니다. 기본값은 False입니다.
torch.randn
torch.randn() 함수는 주어진 크기(size)로 정규 분포(normal distribution)에서 랜덤한 값으로 초기화된 텐서를 생성하는 함수입니다. 텐서의 요소는 평균이 0이고 표준 편차가 1인 정규 분포에서 뽑힙니다.
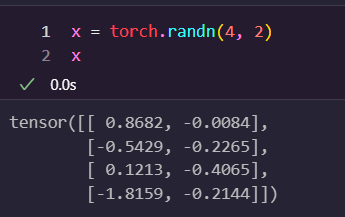
- size: 텐서의 크기를 나타내는 정수 또는 정수 튜플입니다. 예를 들어, torch.randn(2, 3)는 2행 3열 크기의 텐서를 생성합니다.
- out (선택적): 출력 텐서로 사용할 객체입니다. 이 매개변수를 지정하면 함수는 새로운 텐서를 생성하지 않고 주어진 객체를 반환합니다.
- dtype (선택적): 텐서의 데이터 타입을 지정합니다. 기본적으로는 torch.float32로 설정됩니다.
- layout (선택적): 텐서의 메모리 배치 방식을 지정합니다. 기본값은 torch.strided입니다.
- device (선택적): 텐서가 생성될 장치를 지정합니다. 기본적으로는 현재 기본 장치를 사용합니다.
- requires_grad (선택적): 텐서의 연산에 대한 그래디언트(gradient) 계산을 활성화할지 여부를 지정합니다. 기본값은 False입니다.
new_ones
new_ones() 메서드는 주어진 크기(size)로 채워진 텐서를 생성하는 PyTorch의 함수입니다. 이 함수는 모든 요소를 1로 초기화합니다.
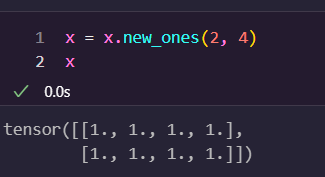
- size: 텐서의 크기를 나타내는 정수 또는 정수 튜플입니다. 예를 들어, torch.new_ones(2, 3)는 2행 3열 크기의 텐서를 생성합니다.
- out (선택적): 출력 텐서로 사용할 객체입니다. 이 매개변수를 지정하면 함수는 새로운 텐서를 생성하지 않고 주어진 객체를 반환합니다.
- dtype (선택적): 텐서의 데이터 타입을 지정합니다. 기본적으로는 입력된 텐서의 데이터 타입과 동일하게 설정됩니다.
- layout (선택적): 텐서의 메모리 배치 방식을 지정합니다. 기본값은 torch.strided입니다.
- device (선택적): 텐서가 생성될 장치를 지정합니다. 기본적으로는 현재 기본 장치를 사용합니다.
- requires_grad (선택적): 텐서의 연산에 대한 그래디언트(gradient) 계산을 활성화할지 여부를 지정합니다. 기본값은 False입니다.
torch.randn_like
주어진 텐서와 동일한 크기(size)로 정규 분포에서 랜덤한 값으로 초기화된 텐서를 생성하는 함수입니다. 생성된 텐서는 주어진 텐서와 동일한 크기와 데이터 타입을 가지며, 평균이 0이고 표준 편차가 1인 정규 분포에서 값을 샘플링합니다.

- input: 기준이 되는 입력 텐서입니다. 생성된 텐서는 이 입력 텐서와 동일한 크기를 가집니다.
- dtype (선택적): 텐서의 데이터 타입을 지정합니다. 기본적으로는 입력 텐서와 동일한 데이터 타입으로 설정됩니다.
- layout (선택적): 텐서의 메모리 배치 방식을 지정합니다. 기본값은 torch.strided입니다.
- device (선택적): 텐서가 생성될 장치를 지정합니다. 기본적으로는 입력 텐서와 동일한 장치를 사용합니다.
- requires_grad (선택적): 텐서의 연산에 대한 그래디언트(gradient) 계산을 활성화할지 여부를 지정합니다. 기본값은 False입니다.
size
PyTorch 텐서의 크기(size)를 반환하는 메서드입니다. 이 메서드는 텐서의 각 차원의 크기를 나타내는 정수들로 구성된 튜플을 반환합니다.

텐서의 연산
ex) 덧셈
1. x + y

2. torch.add(x, y)

3. torch.add(x,y, out=result)

4. inplace 방식

다른 연산자
- torch.sub : 뺄셈
- torch.mul : 곱셉
- torch.div : 나눗셈
- torch.mm : 내적(dot product)
view
텐서의 크기를 변경하는데 사용되는 메서드입니다. view 메서드를 통해 원본 텐서의 원소 개수를 유지하면서 원하는 크기로 텐서를 다시 구성할 수 있습니다.
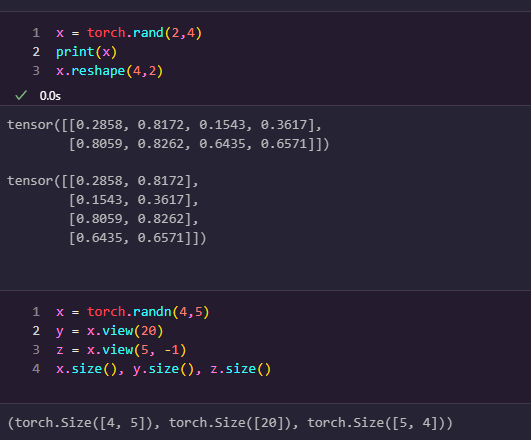
squeeze
함수는 텐서에서 크기가 1인 차원을 제거하는 역할을 합니다. 이는 원본 텐서의 크기를 변경하지 않고, 텐서의 차원을 압축하는 작업을 수행합니다.

unsqueeze
텐서에 새로운 차원을 추가하는 역할을 합니다. 이를 통해 원본 텐서의 크기를 변경하여 차원을 확장할 수 있습니다.

stack
주어진 텐서들을 쌓아서 새로운 차원을 생성하는 역할을 합니다. 이를 통해 여러 개의 텐서를 결합하여 더 높은 차원의 텐서를 생성할 수 있습니다.

cat
텐서를 연결(concatenate)하는 데 사용되는 함수입니다. "cat"은 concatenate의 약자로, 주어진 차원을 따라 텐서들을 연결하는 역할을 합니다. 이 함수를 사용하여 여러 개의 텐서를 하나의 텐서로 결합할 수 있습니다.
- tensors: 연결할 텐서들의 시퀀스입니다. 동일한 모양(shape)을 가진 텐서들끼리만 연결할 수 있습니다.
- dim: 연결할 차원(dimension)을 지정합니다. 기본값은 0이며, 이는 첫 번째 차원(행)을 따라 연결하라는 의미입니다. 다른 차원을 연결하려면 해당 차원의 인덱스를 지정해야 합니다.
- out (선택적): 출력 텐서를 저장할 목적지 텐서입니다. 이를 지정하지 않으면 새로운 텐서가 생성됩니다.

stack vs cat
cat 함수는 기존의 차원에 따라 텐서를 연결합니다. 즉, 연결된 텐서는 기존의 차원을 따라 더 긴 형태로 확장됩니다. 반면에 stack 함수는 새로운 차원을 추가하여 텐서를 연결합니다. 연결된 텐서는 새로운 차원을 가지며, 기존의 차원보다 한 차원이 더 높아집니다.
chunk
주어진 텐서를 특정 차원을 기준으로 여러 개의 작은 청크(chunk)로 나누는 역할을 합니다. 이를 통해 텐서를 작은 부분으로 나누거나, 배치 처리 등에 유용하게 사용할 수 있습니다.

- input: 나눌(input) 텐서입니다.
- chunks: 생성할 청크(chunk)의 개수입니다. input 텐서를 이 개수만큼 동등한 크기로 나눕니다.
- dim: 나눌 차원(dimension)을 지정합니다. 기본값은 0이며, 이는 첫 번째 차원(행)을 기준으로 나누라는 의미입니다. 다른 차원을 기준으로 나누려면 해당 차원의 인덱스를 지정해야 합니다.
split
주어진 텐서를 특정 차원을 기준으로 여러 개의 작은 부분으로 나누는 역할을 합니다. split 함수를 사용하면 텐서를 나누어 각각을 따로 처리하거나, 데이터를 작은 배치 단위로 분할하는 등의 용도로 활용할 수 있습니다.

- tensor: 나눌(input) 텐서입니다.
- split_size_or_sections: 나눌 크기(split size) 또는 나눌 섹션(split sections)을 지정합니다. 크기를 지정하면 해당 크기로 텐서를 동등하게 나눕니다. 섹션을 지정하면 각 섹션마다 나누어질 요소의 개수를 의미합니다.
- dim: 나눌 차원(dimension)을 지정합니다. 기본값은 0이며, 이는 첫 번째 차원(행)을 기준으로 나누라는 의미입니다. 다른 차원을 기준으로 나누려면 해당 차원의 인덱스를 지정해야 합니다.
chunk vs split
chunk 함수는 주어진 텐서를 동등한 크기의 청크로 분할합니다. 즉, 텐서를 동일한 크기의 작은 부분으로 나눕니다. 반면에 split 함수는 크기을 지정하여 텐서를 나눕니다.
torch ↔ numpy
PyTorch 텐서를 NumPy 배열로 변환하기:
numpy()
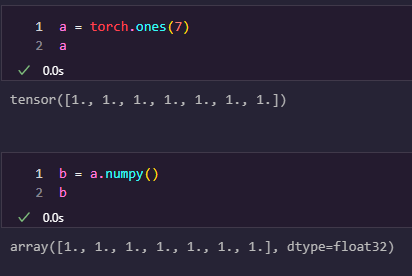
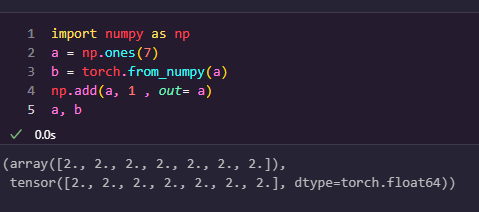
NumPy 배열을 PyTorch 텐서로 변환하기:
torch.from_numpy()
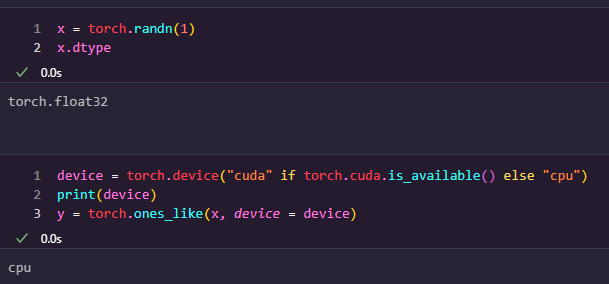
CUDA Tensor
GPU를 활용하기 위한 기능을 제공하는 모듈입니다. cuda 모듈을 사용하여 GPU 메모리에 데이터를 저장하고, GPU를 사용하여 연산을 수행할 수 있습니다. 이를 위해 PyTorch는 torch.Tensor 클래스의 서브클래스인 torch.cuda.Tensor를 제공합니다. `.to` 메소드를 사용하여 텐서를 어떠한 장치로도 옮길 수 있습니다.
'pytorch' 카테고리의 다른 글
| 4. Torchvision, torchvision.transforms (0) | 2023.05.27 |
|---|---|
| 3. nn & nn.funtional (0) | 2023.05.27 |
| 2 - 1. grad can be implicitly created only for scalar outputs 오류 해결 (0) | 2023.05.27 |
| 2. AUTOGRAD (0) | 2023.05.27 |


