
프랙티스만이 살길. 프랙티스만이 살길.
PCA(Principal Component Analysis) 본문
주성분 분석(Principal Component Analysis, PCA)는 데이터의 분포를 가장 잘 설명하는 축(데이터의 변동성을 최대화하는 새로운 축)을 찾아 이 축으로 데이터를 투영하여 차원을 축소합니다.
첫 번째 주성분은 데이터의 분산이 가장 큰 방향이고, 두 번째 주성분은 두번째로 가장 분산이 큰 첫번째 주성분에 직교하는 방향이다.

$\tilde{d}_i = \begin{bmatrix} x_i \\ y_i \\ \end{bmatrix}$는 원래의 데이터를 의미하고,
$\bar{d} = \begin{bmatrix} \bar{x} \\ \bar{y} \\ \end{bmatrix}$는 데이터 들의 평균을 의미한다.
$d_i = \tilde{d}_i - \bar{d}$를 의미해 원점을 중심으로 이동시간 데이터를 의미한다.
데이터 d_i들을 가장 잘설명하는 벡터를 $u$라고 하면 $d_i$의 각 데이터로 부터 norm들의 합이 가장 작을것입니다.
$min \frac{1}{N}\sum_{i=1}^{N}(d_i - d_i^Tu \cdot u)^T(d_i - d_i^Tu \cdot u)$ s.t $\| \mathbf{u} \|_2 = 1$를 풀면되는데 정리하면 다음과 같이 나옵니다. $min -\frac{1}{N}\sum_{i=1}^{N} u^Td_id_i^Tu$
위 식은 다음과 같은데 $min -u^T\frac{1}{N}\sum_{i=1}^{N} (\tilde{d}_i - \bar{d})(\tilde{d}_i - \bar{d})^T$
중간에 covariance matrix를 확인할 수 있습니다. -가 붙어 있으므로 $max u^T\frac{1}{N}\sum_{i=1}^{N} (\tilde{d}_i - \bar{d})(\tilde{d}_i - \bar{d})^T$ 로도 생각할 수 있습니다.
추가예정..어려워서 ㅠ
차원축소
100차원의 벡터를 2차원에 내린다고 했을때
$d_i^Tq_1q_1 + d_i^Tq_2q_2$로 나타낼 수 있습니다. 직 $q_1, q_2$가 span하는 평면에 벡터를 정사영 내렸다고 볼 수 있습니다.
vs 고윳값 분해
고윳값 분해는 하나의 데이터에 대하여 개별적으로 분해를 진행한 것이고, pca는 여러개 데이터의 분포를 토대로 분해를 진행한 것입니다.
vs AE(Auto Encoder)
차원축소의 결과를 다음과 같이 나타낼 수 있습니다.
$d_i^T \begin{bmatrix} q_1 & q_2 & \cdots & q_10\end{bmatrix} \begin{bmatrix} q_1 \\ q_2 \\ \vdots \\ q_10 \end{bmatrix}$
두개의 행렬을 $W, W^T$로 생각하면 하나의 인공신경망처럼 생각할 수 있습니다.
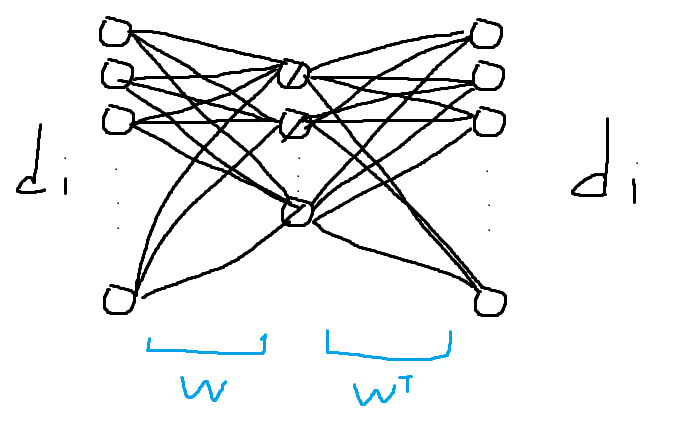
다음과 같이 di에서 di를 내보내는 bottle neck을 가지고 linear한 activation function을 가지는 인공신경망입니다.
여기서 non- linear한 activation function을 사용한다면 오토인코더와 같은 효과를 낼 수 있습니다.
non- linear한 activation function을 사용하게 되면 manifold learning입니다. 이는 pca와 다르게 정사영을 평면이 아닌 곡면에 내리게 됩니다.
'선형대수학' 카테고리의 다른 글
| SVD(Singular Value Decomposition) (0) | 2023.07.14 |
|---|---|
| 고윳값 분해 (0) | 2023.07.05 |
| 고유값, 고유벡터 (0) | 2023.07.03 |
| LSE, normal equation (0) | 2023.07.03 |
| trace (0) | 2023.07.02 |
