
프랙티스만이 살길. 프랙티스만이 살길.
Stock Price Predicting Project 본문
2021년도 수원대 DSML 연구소에서 인턴으로 참여했었던 project입니다. 1학년 학점을 대차게 말아먹고 아무것도 모르는 상태에서 MLP를 처음으로 실제 적용해봤는데,,, 4학년이 된 2024년도말에 정리하다보니 그때 같이 했던 4학년 친구가 정말 고생했구나 생각이듭니다..
저도 많이 베풀면서 살아야겠습니다.
Finance Data Reader로 주식 데이터 불러오기
about Finance Data Reader : https://financedata.github.io/posts/finance-data-reader-users-guide.htmld
FinanceDataReader 사용자 안내서
FinanceDataReader 사용자 안내서
financedata.github.io
전체 종목코드를 받아 2018-1-2일 전에 상장했고, 3년 이상 존속한 종목만 필터링했습니다.
(Train Data : 2018-01-01~2020-12-31 , Test Data : 2021-01-01~2021-06-30)

fdr.DataReader을 사용해 특정 코드의 주식데이터를 불러올 수 있습니다.
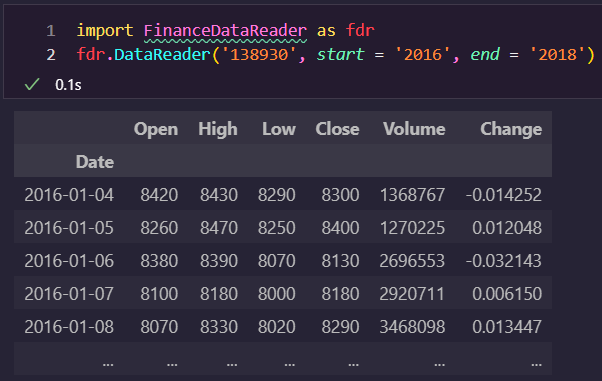
개장일, 시가, 고가, 저가, 종가, 거래량, 전날대비 변화률을 column으로 가지고 있습니다.
보조지표 추가
개장일, 시가, 고가, 저가, 종가, 거래량, 전날대비 변화률만으로는 데이터를 설명하기 힘듭니다.
ta라이브러리를 사용해 보조지표를 추가했습니다.
about ta : https://technical-analysis-library-in-python.readthedocs.io/en/latest/ta.html
Documentation — Technical Analysis Library in Python 0.1.4 documentation
Rate of Change (ROC) The Rate-of-Change (ROC) indicator, which is also referred to as simply Momentum, is a pure momentum oscillator that measures the percent change in price from one period to the next. The ROC calculation compares the current price with
technical-analysis-library-in-python.readthedocs.io

보조지표를 추가한 matrix입니다. 총 col은 52개로 52 - 7 = 45개의 보조지표가 추가되었습니다.
Target 정의
거래대금이 1조 이상인 날짜를 D-day로 지정하여, D-9 ~D-day까지의 feature로 다음날 변화량이 5% 이상 상승여부를 Target로 설정했습니다.
연구설계에서부터 LSTM을 염두하고 있음이 느껴집니다.. 이유는 간단한데 단순히 feature를 떄려넣고 MLP, XGBoost를 돌렸더니 전혀 학습이 안됐기 떄문입니다.
거래대금 1조 이상으로 filtering하고 5%이상의 상승여부를 boundary로 정한것은 실험에 근거했습니다.
Scailing
stock데이터에서는 특히나 Scailing이 중요합니다. 보통은 feature의 scale이 다른데 stock data는 주식종목마다, feature마다 scale이 모두 다르기 떄문입니다.
MINMAX scaler를 사용했습니다.
Over Sampling
SMOTE로 데이터 불균형 해결하기
현실 세계의 데이터는 생각보다 이상적이지 않다.
john-analyst.medium.com
거래대금이 1조 이상인 날짜를 D-day로 지정하여, D-9 ~D-day까지의 feature로 다음날 변화량이 5% 이상 상승여부를 Target로 설정했다고 말씀드렸습니다. 문제는 target이 1일때(5%이상일때)가 너무 적다는 것입니다.
데이터 불균형이 약 93:7정도로 관측되었습니다.
train의 shape:
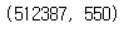
smote를 이용하여 비율을 맞춰주었습니다.
LSTM으로 예측하기
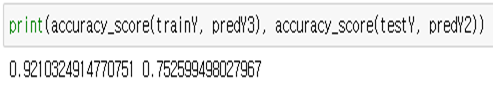
LGBM, Logistic Regression, LSTM을 사용한 결과 LSTM이 가장좋은 성능을 보여줬습니다.
구매전략
갓 2학년이 된 저는 아무것도 모르는 무지랭이였기에 더 이상 연구를 전진할 수가 없었습니다... 지금 이런걸 연구할 기회가 온다면 참 잘할 수 있을것 같은데.... 역량이 갖춰지니 학교를 떠날때가 되어버렸습니다. 그래서 대학원으로 꼭 떠나야겠습니다.
그래도 독창적인 결과를 내고 싶은 마음에 개발한 모델을 이용한 효과적인 구매 전략을 연구했었습니다.
과정은 다음과 같습니다
1. 데이터 분류
각 주식에 투자할 비율을 정하기 위해 예측 값의 probability 값을 출력함.
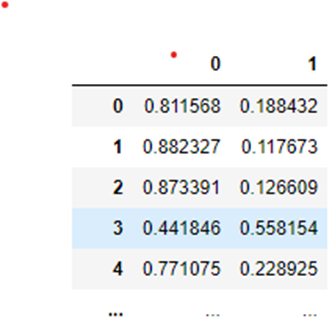
2. 분포 시각화
(0.0~ 0.4) 사이에 가우시안 분포shape으로 데이터가 집중되어있음을 확인할 수 있음.
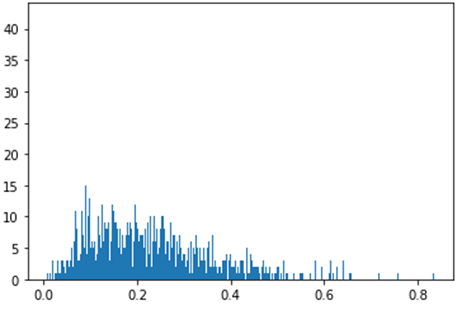
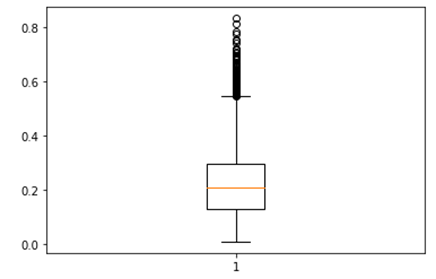
3. 데이터 분류의 기준
데이터 분류의 기준을 정하기 위해 사분위수를 구하고, 기준으로 삼음.
기준에 따라 차등적으로 투자금액의 비율을 정함.
4. 판매 비율
4분위수 이상은 25%, 3분위수 이상은 가진 돈의 20%만큼 구매하기로 함. 모든 구매 주식은 다음날 전량 판매.
5. 결과
수익률 그래프:
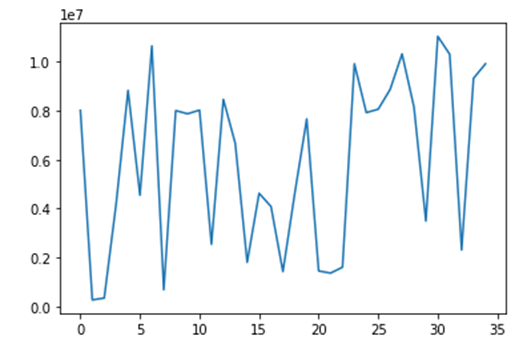
수익률 비교:

회고:
저의 첫 ai, 파이썬 프로젝트로 시행착오가 참 많았습니다. 처음으로 Toy Data가 아닌 real Bigdata를 다루다보니 시간복잡도에서 문제가 많았습니다. 랩실에 방학동안 매일매일 출근하면서 고민과 절망하던 기억이 나네요.
이래저래 부딪쳐가며 정말 많이 배웠던 인턴쉽이였던 것 같습니다. 다만 아쉬운건 시간이 많이 흐른상태에서 정리하다보니 자료가 너무 많이 소실되어 github에 정리도 못하고 시각화 자료도 많이 사라졌네요... 역시 정리는 바로바로!
'Project' 카테고리의 다른 글
| AutoEncoder를 이용한 공기압축기 이상판단 (0) | 2023.09.13 |
|---|---|
| Mimic Dataset disease analysis(mimic 의료 데이터 분석) (0) | 2023.09.13 |
| Healthnutrition(독거노인 질병분석) (1) | 2023.09.13 |


